The following is a synthesis of the final logical steps in concluding my Master's thesis, on the ECM (Enterprise Content Management) topic of "Suitability of Large Language Models for Making PDF-Documents More Accessible and Barrier-free (in Enterprise Content Management)" - the thesis itself has a broader view, here the focus is on the LLM/ML-tooling used in evaluation of LLM output on the task itself, with a view to advancing in this area as LLMs become more powerful and capable, and/or fine-tuned LLMs including tuning on this task or adjacent ones are produced (or in combination, powerful, fine-tuned LLMs).
Note: some of the information is generated by ChatGPT 5 in the context of the thesis work this blog post pertains to.
Meta-informational Approach
We start from a fine-tuning regime; here is the code assembled for a Google Colab A100 setup.
%%capture
import os
if "COLAB_" not in "".join(os.environ.keys()):
!pip install unsloth
else:
# Do this only in Colab notebooks! Otherwise use pip install unsloth
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf "datasets>=3.4.1" huggingface_hub hf_transfer
!pip install --no-deps unsloth
!pip install pymupdf orjson
from unsloth import FastLanguageModel
import torch
max_seq_length = 4096 # A100 is fine with this. You can try 8192 if your model supports it.
dtype = None # None for auto; on A100 this will pick bfloat16.
load_in_4bit = True # QLoRA-style training; keeps VRAM low.
# 4bit pre-quantized models we can swap in quickly:
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/gemma-2-9b-bnb-4bit",
]
# Use any compatible 8B/7B. (You can switch this later to a DeepSeek-distill variant if Unsloth supports it.)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B", # try the -Instruct-bnb-4bit variant too
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # if you use gated models
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # try 32 or 64 on A100 if you want more capacity
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0, # =0 is optimized in Unsloth
bias = "none",
use_gradient_checkpointing = "unsloth", # great for long context
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
We work from a drive where we have a finetuning folder with training documents. The setting is like this, per document:
- non barrier-free version
- the manually edited, barrier-free version tagged ` bf` (with a preceeding space) before the file ending
- an accessibility report ending in
_a11y.json(preceeding underscore) - more on this below
These details are included in case you want to recreate the setup, re-use this code, and contribute to the project of advancing in this area of LLM applications.
from google.colab import drive
drive.mount('/content/drive')
from pathlib import Path
import fitz # PyMuPDF
from datasets import Dataset
import orjson
import json
import re
# --- Parameters ---
# Directory in Drive containing pairs like:
# foo_uncompressed.pdf (source)
# foo_bf_uncompressed.pdf (gold, manually made accessible)
# foo_a11y.json OR foo_a11y.txt (optional report)
finetuning_dir = Path("/content/drive/MyDrive/finetuning")
# Keep inputs/outputs complete by default.
# Set to a VERY high limit or None to disable. Keeping None = no truncation.
max_lines = None # e.g. set to 100000 if you need a cap
# If your reports are extremely long, you can cap them independently:
max_report_chars = None # e.g. 100000; None = no cap
# Instruction prompt (domain-specific, terse, no CoT exposure)
instruction = """You are a low-level PDF accessibility fixer.
INPUTS:
1) PDF_CODE_RAW: Decompressed PDF page content streams (text operators, XObjects, structure refs).
2) ACCESSIBILITY_REPORT: Concrete issues to fix (missing /Alt, reading order, headings, structure tree, lang, etc.).
TASK:
Rewrite the PDF content streams to produce an accessible version. Fix issues per the report and PDF/UA best practices.
RESPONSE FORMAT:
Return ONLY the improved PDF content streams. No commentary, no markdown, no extra text.
"""
# --- Helper to extract /Contents stream from each page ---
def extract_content_streams(pdf_path: Path) -> str:
doc = fitz.open(str(pdf_path))
contents = []
for page in doc:
contents_obj = page.get_contents()
if isinstance(contents_obj, list):
for xref in contents_obj:
stream = doc.xref_stream(xref)
if stream:
contents.append(stream.decode(errors="ignore"))
elif contents_obj:
stream = doc.xref_stream(contents_obj)
if stream:
contents.append(stream.decode(errors="ignore"))
doc.close()
return "\n".join(contents)
def read_accessibility_report(base: str, folder: Path) -> str:
"""
Looks for {base}_a11y.json or {base}_a11y.txt
Returns raw text. If JSON, pretty-prints compactly.
"""
json_path = folder / f"{base}_a11y.json"
txt_path = folder / f"{base}_a11y.txt"
if json_path.exists():
try:
with open(json_path, "rb") as f:
data = orjson.loads(f.read())
# Compact but readable JSON as text
return orjson.dumps(data, option=orjson.OPT_INDENT_2).decode("utf-8")
except Exception as e:
print(f"Warning: Failed to parse JSON report for {base}: {e}")
if txt_path.exists():
try:
return txt_path.read_text(encoding="utf-8", errors="ignore")
except Exception as e:
print(f"Warning: Failed to read TXT report for {base}: {e}")
return "" # OK if missing
The following is good for checking everything is loading correctly:
# --- Create instruction-style dataset (complete documents) ---
examples = []
bf_files = sorted(finetuning_dir.glob("*_bf_uncompressed.pdf"))
print(f"Found {len(bf_files)} gold (accessible) PDFs.")
for bf_path in bf_files:
base = bf_path.name.replace("_bf_uncompressed.pdf", "")
src_path = finetuning_dir / f"{base}_uncompressed.pdf"
try:
if not src_path.exists():
print(f"Warning: Missing source for {bf_path.name}, skipping.")
continue
# Extract full streams
src_code = extract_content_streams(src_path)
tgt_code = extract_content_streams(bf_path)
report = read_accessibility_report(base, finetuning_dir)
# Optional caps (disabled by default)
if max_lines is not None:
src_code = "\n".join(src_code.splitlines()[:max_lines])
tgt_code = "\n".join(tgt_code.splitlines()[:max_lines])
if max_report_chars is not None and report:
report = report[:max_report_chars]
# Previews for logging
input_preview = (src_code[:200] if src_code else "").replace("\n", "\\n")
output_preview = (tgt_code[:200] if tgt_code else "").replace("\n", "\\n")
report_preview = (report[:200] if report else "").replace("\n", "\\n")
print(
f"Adding example {base}:\n"
"--- Input (first 200 chars) ---\n"
f"{input_preview}\n"
"--- Report (first 200 chars) ---\n"
f"{report_preview}\n"
"--- Output (first 200 chars) ---\n"
f"{output_preview}\n"
)
# Single, complete example
examples.append({
"instruction": instruction,
# We keep raw + report as a single "input" block to preserve completeness.
"input": f"PDF_CODE_RAW:\n{src_code}\n\nACCESSIBILITY_REPORT:\n{report}",
"output": tgt_code
})
except FileNotFoundError:
print(f"Error: File not found: {src_path}. Skipping.")
except Exception as e:
print(f"Error processing pair {bf_path.name}: {e}")
print(f"Prepared {len(examples)} examples.")
Pouring it into the Alpaca format (Unsloth):
# --- HuggingFace Dataset + Unsloth Prompt Formatting (Alpaca-style) ---
from datasets import Dataset
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(batch):
texts = []
for i, inp, out in zip(batch["instruction"], batch["input"], batch["output"]):
# Keep documents COMPLETE; no extra wrappers.
texts.append(alpaca_prompt.format(i, inp, out) + EOS_TOKEN)
return {"text": texts}
dataset = Dataset.from_list(examples)
dataset = dataset.map(formatting_prompts_func, batched=True, remove_columns=list(dataset.features.keys()))
print(dataset[:1]["text"][0][:1000])
Training procedure:
# Training
from trl import SFTConfig, SFTTrainer
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset, # If you have a separate val set, pass eval_dataset=...
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Keep each document intact (no packing)
args = SFTConfig(
per_device_train_batch_size = 2, # A100 can usually do 2–4 with 4-bit
gradient_accumulation_steps = 4, # effective batch size 8
warmup_steps = 50,
# num_train_epochs = 3, # or use steps:
max_steps = 1000, # adjust to your dataset size
learning_rate = 2e-4,
logging_steps = 5,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "cosine",
seed = 3407,
output_dir = "outputs",
report_to = "none",
bf16 = True, # good on A100
gradient_checkpointing = True,
save_steps = 200,
save_total_limit = 2,
),
)
Notes on the Alpaca format:
- Comes from the Stanford Alpaca dataset (2023).
- Each example has three fields:
instruction,input, andoutput. - They are combined into a fixed template, which helps the model learn instruction-following
Unsloth is a fine-tuning library optimized for LLMs (LoRA/QLoRA training):
- It doesn’t change the format — it just trains more efficiently.
Notes on the trainer itself:
- dataset_text_field = "text"
- Trainer reads Alpaca-style strings from the
textcolumn.
- Trainer reads Alpaca-style strings from the
- packing = False
- Each row is treated as a full sequence.
- Easier to debug, but less GPU-efficient (padding overhead).
- max_seq_length = max_seq_length
- Longer samples truncated, shorter ones padded.
- Must be ≤ model’s context window.
- per_device_train_batch_size = 2
- Small per-GPU batch.
- gradient_accumulation_steps = 4
- Effective batch size = 2 × 4 = 8 (per device).
- warmup_steps = 50
- Linear warmup before LR schedule kicks in.
- max_steps = 1000
- Train for a fixed number of steps.
- Alternative: use
num_train_epochs.
- learning_rate = 2e-4
- Standard for LoRA/QLoRA.
- Too high for full fine-tune.
- optim = "adamw_8bit"
- 8-bit AdamW via bitsandbytes.
- Saves memory with minimal overhead.
- weight_decay = 0.01
- Regularization on weights.
- lr_scheduler_type = "cosine"
- Smooth decay after warmup.
- Good default for SFT.
- bf16 = True
- Efficient on A100/H100 GPUs.
- Use
fp16=Trueif bf16 unsupported.
- gradient_checkpointing = True
- Saves memory, extra compute cost.
- logging_steps = 5
- Logs loss/metrics frequently.
- report_to = "none"
- No external logging.
- Switch to
"wandb"/"tensorboard"if desired.
- save_steps = 200
- Save checkpoints every 200 steps.
- save_total_limit = 2
- Keep only the 2 most recent checkpoints.
- dataset_num_proc = 2
- Two CPU workers for dataset preprocessing.
- output_dir = "outputs"
- Checkpoints and logs saved here.
- seed = 3407
- Reproducibility.
Memory check:
# @title Show current memory stats
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
Actual training loop:
# Train
trainer_stats = trainer.train()
My learning rate graph (training set of about 100 document pairs and their respective accessibility reports, based on Adobe PDF Services) follows.
Comparison with training without meta-informational enrichment
The same training procedure was run on the same training documents, but without reports: at training time, we get the following training performance. (Different context sizes were tested, the model was Llama3.1 (8B).)
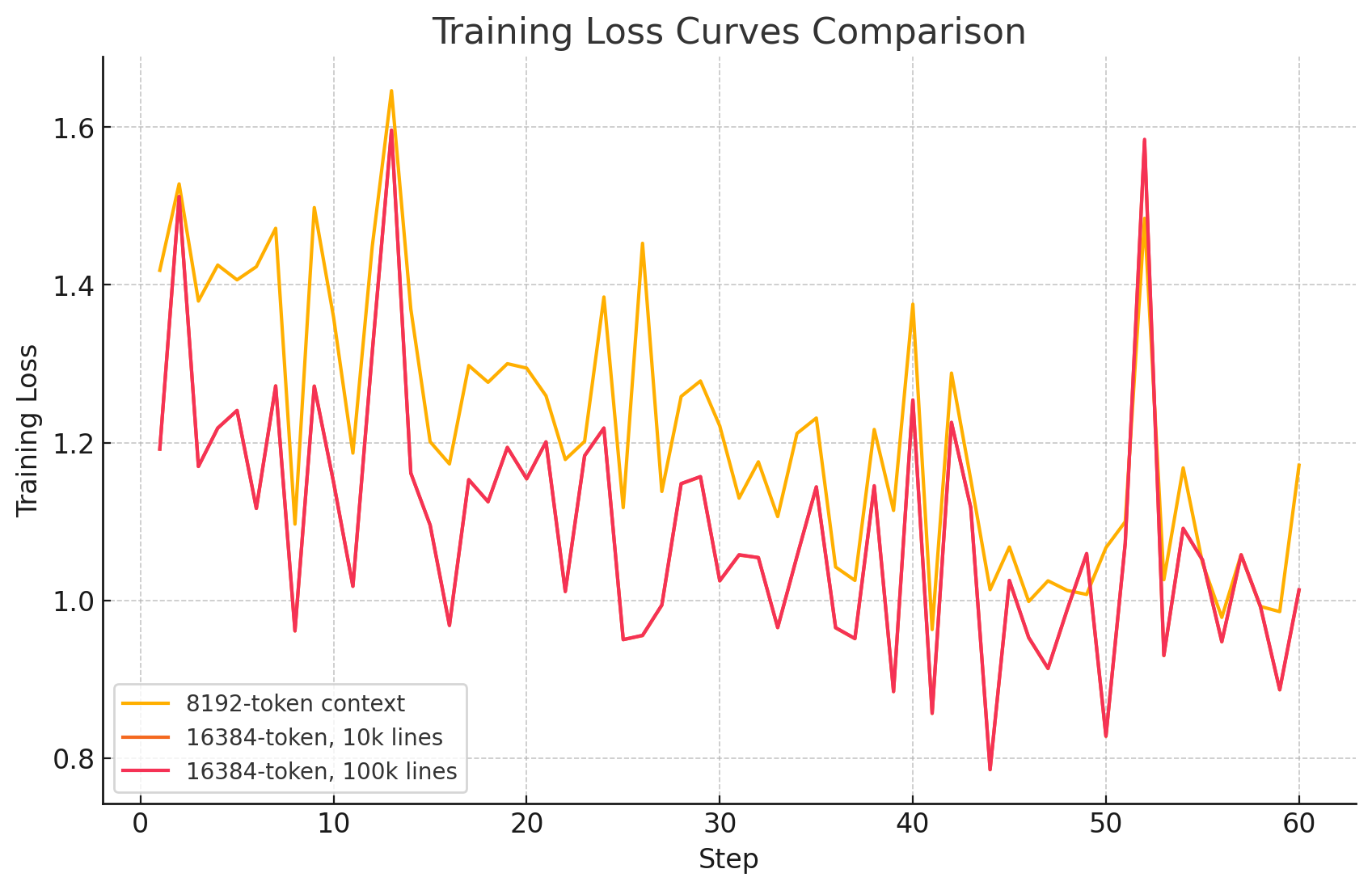
We will consider testing, for both scenarios, in the next section.
Accessibility Reports
Code, building on Adobe PDF Services (requiring this service's API credentials, id and key), also made for Google Colab and compatible with the directory setup described:
%%capture
# Install Adobe PDF Services SDK 4.x (Python >= 3.10 on Colab)
!pip -q install --upgrade pip
!pip -q install "pdfservices-sdk==4.2.0"
# (Re)confirm credentials are present (masked print for sanity)
import os, getpass
cid = os.getenv("PDF_SERVICES_CLIENT_ID")
csec = os.getenv("PDF_SERVICES_CLIENT_SECRET")
if not cid:
cid = input("Enter PDF_SERVICES_CLIENT_ID: ").strip()
os.environ["PDF_SERVICES_CLIENT_ID"] = cid
if not csec:
csec = getpass.getpass("Enter PDF_SERVICES_CLIENT_SECRET (hidden): ").strip()
os.environ["PDF_SERVICES_CLIENT_SECRET"] = csec
print("PDF_SERVICES_CLIENT_ID:", (cid[:4] + "…" + cid[-4:]) if cid and len(cid) >= 8 else "missing")
print("✅ Credentials set.")
Intended to run over a whole (Google Drive) directory, the same that is then used for training.
# Force-remount Drive once (helps after FUSE errors)
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
print("✅ Drive mounted.")
# Core script (fixed credentials check + drive-safe writing + correct imports)
import os, re, json, time, logging, errno
from pathlib import Path
from typing import Optional, Tuple
from adobe.pdfservices.operation.auth.service_principal_credentials import ServicePrincipalCredentials
from adobe.pdfservices.operation.pdf_services import PDFServices
from adobe.pdfservices.operation.io.stream_asset import StreamAsset
from adobe.pdfservices.operation.io.cloud_asset import CloudAsset
from adobe.pdfservices.operation.pdf_services_media_type import PDFServicesMediaType
from adobe.pdfservices.operation.pdfjobs.jobs.pdf_accessibility_checker_job import PDFAccessibilityCheckerJob
from adobe.pdfservices.operation.pdfjobs.result.pdf_accessibility_checker_result import PDFAccessibilityCheckerResult
from adobe.pdfservices.operation.exception.exceptions import ServiceApiException, ServiceUsageException, SdkException
LOG = logging.getLogger("a11y-colab")
logging.basicConfig(level=logging.INFO, format="%(levelname)s: %(message)s")
# -------- Helpers --------
def get_pdf_services() -> PDFServices:
client_id = os.environ.get("PDF_SERVICES_CLIENT_ID")
client_secret = os.environ.get("PDF_SERVICES_CLIENT_SECRET")
if not client_id or not client_secret:
raise RuntimeError("Missing PDF_SERVICES_CLIENT_ID or PDF_SERVICES_CLIENT_SECRET.")
creds = ServicePrincipalCredentials(client_id=client_id, client_secret=client_secret)
return PDFServices(credentials=creds)
def safe_write_json_bytes(report_path: Path, json_bytes: bytes, attempts: int = 3) -> None:
"""Write JSON to Drive with retries. On Drive FUSE error, remount and retry, then fallback to /content."""
for i in range(attempts):
try:
# Prefer pretty text if valid JSON
try:
data = json.loads(json_bytes.decode("utf-8"))
report_path.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")
except Exception:
report_path.write_bytes(json_bytes)
return
except OSError as e:
LOG.warning(f"Write attempt {i+1}/{attempts} failed for {report_path.name}: {e}")
# If Drive FUSE flaked, try remount then retry
from google.colab import drive as gc_drive
try:
gc_drive.mount('/content/drive', force_remount=True)
except Exception:
pass
time.sleep(1.0)
# Fallback to local if Drive keeps failing
fallback_dir = Path("/content/a11y_reports_fallback")
fallback_dir.mkdir(parents=True, exist_ok=True)
fallback_path = fallback_dir / report_path.name
try:
data = json.loads(json_bytes.decode("utf-8"))
fallback_path.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")
except Exception:
fallback_path.write_bytes(json_bytes)
LOG.error(f"Drive write failed repeatedly. Saved locally to: {fallback_path}")
# -------- File selection & naming --------
BF_PATTERNS = [
r"[ _-]bf_uncompressed\.pdf$",
r"[ _-]bf\.pdf$",
]
UNCOMPRESSED_PAT = r"_uncompressed\.pdf$"
def looks_accessible_variant(name: str) -> bool:
low = name.lower()
return any(re.search(p, low) for p in BF_PATTERNS)
def is_uncompressed_source(name: str) -> bool:
return re.search(UNCOMPRESSED_PAT, name.lower()) is not None
def is_plain_pdf(name: str) -> bool:
return name.lower().endswith(".pdf") and not is_uncompressed_source(name) and not looks_accessible_variant(name)
def base_for_report(pdf_path: Path) -> str:
base = pdf_path.stem
base = re.sub(r"[ _-]bf_uncompressed$", "", base, flags=re.IGNORECASE)
base = re.sub(r"[ _-]bf$", "", base, flags=re.IGNORECASE)
base = re.sub(r"_uncompressed$", "", base, flags=re.IGNORECASE)
return base.strip()
def report_path_for(pdf_path: Path) -> Path:
base = base_for_report(pdf_path)
return pdf_path.with_name(f"{base}_a11y.json")
# -------- Adobe job runner with retry/backoff --------
def run_accessibility_check(pdf_bytes: bytes, retries: int = 3, backoff: float = 2.0) -> bytes:
pdf_services = get_pdf_services()
attempt = 0
while True:
try:
input_asset = pdf_services.upload(input_stream=pdf_bytes, mime_type=PDFServicesMediaType.PDF)
job = PDFAccessibilityCheckerJob(input_asset=input_asset)
location = pdf_services.submit(job)
resp = pdf_services.get_job_result(location, PDFAccessibilityCheckerResult)
report_asset: CloudAsset = resp.get_result().get_report()
stream_report: StreamAsset = pdf_services.get_content(report_asset)
return stream_report.get_input_stream() # raw bytes (JSON)
except (ServiceApiException, ServiceUsageException, SdkException) as e:
attempt += 1
if attempt > retries:
raise
sleep_for = backoff * (2 ** (attempt - 1))
LOG.warning(f"API error {type(e).__name__}: {e}. Retrying in {sleep_for:.1f}s...")
time.sleep(sleep_for)
# -------- Directory traversal --------
def choose_sources(pdf_files: list[Path]) -> list[Path]:
selected = []
for p in pdf_files:
name = p.name
if looks_accessible_variant(name):
continue
if is_uncompressed_source(name) or is_plain_pdf(name):
selected.append(p)
return selected
def process_one(pdf_path: Path, overwrite: bool = False) -> Optional[Path]:
report_path = report_path_for(pdf_path)
if report_path.exists() and not overwrite:
LOG.info(f"Skip (exists): {report_path.name}")
return None
LOG.info(f"Checking: {pdf_path.name}")
pdf_bytes = pdf_path.read_bytes()
json_bytes = run_accessibility_check(pdf_bytes)
safe_write_json_bytes(report_path, json_bytes)
LOG.info(f"Saved: {report_path.name}")
return report_path
def process_dir(root: Path, overwrite: bool = False, only_paired: bool = True, recursive: bool = False) -> Tuple[int, int]:
if recursive:
pdfs = sorted([p for p in root.rglob("*.pdf") if p.is_file()])
else:
pdfs = sorted([p for p in root.iterdir() if p.suffix.lower() == ".pdf" and p.is_file()])
if not pdfs:
LOG.warning("No PDFs found.")
return (0, 0)
candidates = choose_sources(pdfs)
if only_paired:
bf_bases = set(base_for_report(p) for p in pdfs if looks_accessible_variant(p.name))
candidates = [p for p in candidates if base_for_report(p) in bf_bases]
made, skipped = 0, 0
for src in candidates:
try:
out = process_one(src, overwrite=overwrite)
if out is None:
skipped += 1
else:
made += 1
except Exception as e:
LOG.error(f"Failed: {src.name} -> {e}")
return (made, skipped)
print("✅ Batch generator (fixed) loaded.")
Execution
# Run over your finetuning folder
from pathlib import Path
finetuning_dir = Path("/content/drive/MyDrive/finetuning") # change if needed
OVERWRITE_EXISTING = False
ONLY_PAIRED = True
RECURSIVE = False
made, skipped = process_dir(finetuning_dir, overwrite=OVERWRITE_EXISTING, only_paired=ONLY_PAIRED, recursive=RECURSIVE)
print(f"Done. Created: {made}, Skipped: {skipped}")
Testing Set and Results
12-Document-Test Set
In my thesis I formally evaluate the (fine-tuned) models and uncover relatively low scoring in the chosen model classes, fine-tuning regime, and code setup: by formalizing the test set with a particular use case in mind, however, a contribution for future model evaluations is made, with a certain application context in mind (in this case, German language and General Accident Insurance as the domain - this context may be added to in the future) and with the hope for improvements. The test set is provided with this thesis and encompasses 12 test documents - by permission of AUVA it is also available online, in the project repository for the thesis.
Fine-tuned Models (No Meta-info) First Tests on Test Set
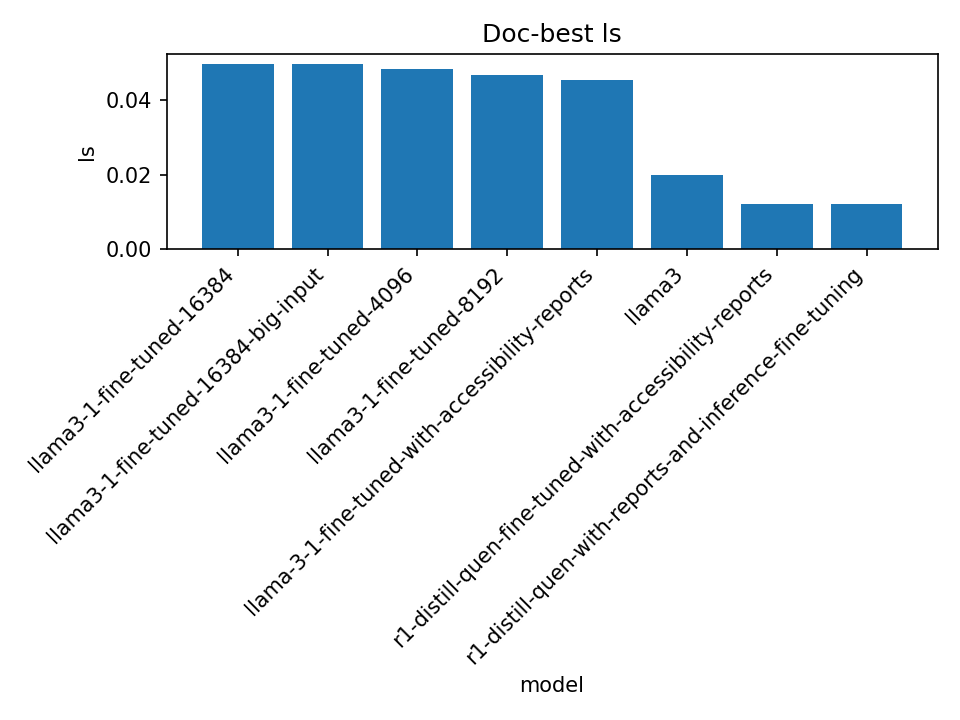
We bring the fine-tuned model to bear on the full test set of 12 documents for the main discussion of results. In aggregate, the fine-tuned llama3-1 variants do not close the overlap gap: model-average BLEU, ROUGE-L(F_1), and METEOR remain low (near 0–0.05 across documents), and the doc-best scores are only marginally higher than the per-model averages. Normalized edit metrics continue to be the most informative: LR sits in the mid range ("moderate closeness"), LS drops when hypotheses are much longer than references, and CER/WER spike under length bloat or when extracted token streams collapse to very short sequences. A consistent pattern across the 12 documents is stability without quality gains: fine-tuned outputs are often deterministic (small variance across responses), which helps consistency but also hints at mode collapse on some inputs. Overall, the fine-tuned models track the non-fine-tuned llama3 baselines in shape/length space while failing to improve token-level overlap.
See the following note on methodology to explain the above excerpt.
Note on Metrics
We evaluate accessible-PDF generation as a sequence-to-sequence task, comparing model output to ground-truth references using complementary NLP metrics:
- BLEU (↑ higher is better)
- Measures local n-gram precision with a brevity penalty.
- High BLEU → correct tag/attribute reproduction in correct order.
- ROUGE (↑ higher is better)
- Emphasizes recall of reference content.
- ROUGE-N: overlap of n-grams (e.g., unigrams, bigrams).
- ROUGE-L: longest common subsequence.
- High ROUGE → candidate covers most reference tokens, tolerant of extra output.
- METEOR (↑ higher is better)
- Combines precision + recall (recall weighted more heavily).
- Includes stemming, synonymy, paraphrase, and order penalty.
- High METEOR → good coverage with flexibility for reordered/variant tags.
- Edit Distance (↓ lower is better)
- Levenshtein distance: minimum edits (insertions, deletions, substitutions) to match reference.
- Low distance → fewer corrections needed for valid accessible PDF.
Interpretation
- BLEU → Exactness of local structures.
- ROUGE → Coverage of reference content.
- METEOR → Balanced correctness with order tolerance.
- Edit Distance → Practical correction effort.
Consistent improvement across BLEU, ROUGE, METEOR (↑), and Edit Distance (↓) indicates better alignment of generated PDFs with accessibility-ground-truth.
Length-normalized Edit Similarities
To complement raw Levenshtein distance d = lev(R, C) (reference R, candidate C), we normalize by string length to obtain error rates and similarity scores:
- CER (Character Error Rate) ↓
CER = d / |R|- Edit distance normalized by reference length at character level.
- Lower is better → fewer character edits per reference character.
- WER (Word Error Rate) ↓
WER = d_w / |R_w|- Edit distance at token level (words instead of characters).
- Lower is better → fewer word-level corrections needed.
- Levenshtein Similarity (LS) ↑
LS = 1 - d / max(|R|, |C|)- Strict similarity: divides by the longer string length.
- Penalizes heavily when candidate is much longer than reference.
- Levenshtein Ratio (LR) ↑
LR = (|R| + |C| - d) / (|R| + |C|)- More robust to length skew (normalizes by total combined length).
- Always
LR ≥ LSwhend > 0.
Interpretation
- CER / WER → error rates (lower = better).
- LS / LR → similarity scores (higher = better).
- LS is stricter (penalizes overlong outputs).
- LR is more forgiving, balancing both lengths.
Together, these metrics complement BLEU/ROUGE/METEOR by quantifying edit effort per unit length and giving a normalized similarity measure between 0 and 1.
Now we have a solid background to look at the test set evaluation scores.
Comparison of Fine-tuned Models (with/without Meta-info)
We pick some of the available plots, starting with Edit Distances and related ratios.
(Again/Detail:) Fine-tuned Models without Meta-information
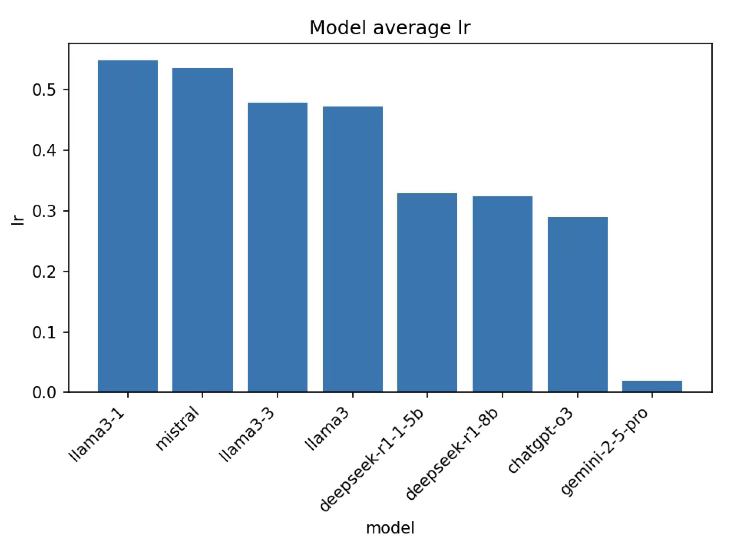
Model-average LR (Levenshtein Ratio, higher is better): Locally run models ranked by normalized edit similarity to references: LR summarizes closeness after accounting for length; higher bars indicate candidates that are closer in edit space. (Llama3.1 performs the best on this task, but not particularly well.)
Fine-tuned Models with Meta-information
We test a hypothesis that accessibility reports, of the type obtained in the first part of this thesis work, a practical ECM implementation, but notice that these actually perform worse, for both Llama3.1 and also "reasoning" models, like Deepseek's R1.
Example Output
In a sense this was the most complete experiment, accessibility report training with a thinking model: so what does an output actually look like? Here is one example output, from the test set:
%PDF-1.3
3 0 obj
<</Type /Page
/Parent 1 0 R
/Resources 2 0 R
/Contents 4 0 R>>
endobj
4 0 obj
<</Filter /FlateDecode /Length 357>>
stream
x��R=OC1
��
�� q�T|&o�L �@!�>n��Ph;@�X���� \
����r��)
���'��I��7Cw��a�8�&x|����R
�tf����<´!}1�pN1L��1�#Xj�k�bܪ�V�qf��ű�{ܽ
d55:��ش����8!8~
!bX[�\
Mk�Z6KGim-��k�<d
א�Un���7�V[w=y���-���Zk9Ai��%[��șD-U������' �k
��nԛk`�Ns��
����Z?�������8�f�ɸ���&;�ރ������ZE�):ʚ
[�#ah��#�ȱ%:"���",m[t�����tOt�
��9:��|'�rGr>���
endstream
endobj
5 0 obj
<</Type /Page
/Parent 1 0 R
/Resources 2 0 R
/Contents 6 0 R>>
endobj
6 0 obj
<</Filter /FlateDecode /Length 356>>
stream
x����NC1
�w��c;��v
;kE���n� T$P���oʂ� $�,Q|�s�ǰ�H�_�fKbL �
,��J��UE3�a��0����̭:��O���K�b�$7�[/��&MD�ѝ���VGV��@
E/�0�lX��
���YqF�f��5c�u��l\��V,�IVCɭi)y�u
���M�s��%�U�
�����g��9a�]�HI�Ħ�Av&����4�k��ߣgJ5�l'.�9V\*��#�~�xj6���z�����z�8��Oؐ�!t�:���5@��#���L�I8
@�]Q���jH~�
fG?:��z
2F�'ѡ
/=��b���ɟ�����K
endstream
endobj
7 0 obj
<</Type /Page
/Parent 1 0 R
/Resources 2 0 R
/Contents 8 0 R>>
endobj
8 0 obj
<</Filter /FlateDecode /Length 322>>
stream
x��R�N1
��
�7�c;Y+ZD'�q
��H���H�>�
BB)�%���{~��I@1��,:��(b��`�
OLH��A��鲛A�����)����&�㡅p�0>��D�+�JĜ)�V�d�BE
XɵD�̒��Y��o�4G�\��ڢ$
���r ����DA-r��r�EOK(�R��H��a6�1��'�$r̤h�i;Ϣ�UR@�Q�FF�#��+�H2_
�v��2c����k�P�e���fL~�QH�p��Z�>*U��~z�����z�)���nݶDè�������=�:�"����iۉ���o_6�������_��P
endstream
endobj
1 0 obj
<</Type /Pages
/Kids [3 0 R 5 0 R 7 0 R ]
/Count 3
/MediaBox [0 0 595.28 841.89]
>>
endobj
9 0 obj
<</Type /Font
/BaseFont /Helvetica
/Subtype /Type1
/Encoding /WinAnsiEncoding
>>
endobj
2 0 obj
<<
/ProcSet [/PDF /Text /ImageB /ImageC /ImageI]
/Font <<
/F1 9 0 R
>>
/XObject <<
>>
>>
endobj
10 0 obj
<<
/Producer (PyFPDF 1.7.2 http://pyfpdf.googlecode.com/)
/CreationDate (D:20250922123741)
>>
endobj
11 0 obj
<<
/Type /Catalog
/Pages 1 0 R
/OpenAction [3 0 R /FitH null]
/PageLayout /OneColumn
>>
endobj
xref
0 12
0000000000 65535 f
0000001488 00000 n
0000001683 00000 n
0000000009 00000 n
0000000087 00000 n
0000000514 00000 n
0000000592 00000 n
0000001018 00000 n
0000001096 00000 n
0000001587 00000 n
0000001787 00000 n
0000001897 00000 n
trailer
<<
/Size 12
/Root 11 0 R
/Info 10 0 R
>>
startxref
2001
%%EOF
Large Language Models are designed to generate sequences of text, not arbitrary bytes. Since binary files often include values that do not map cleanly to text characters, direct generation of binary can lead to corruption or loss of information. To safely handle binary, LLMs usually output encodings such as Base64 or hexadecimal, which represent binary data in a text-friendly format that can later be decoded back into the original binary form. This approach allows LLMs to effectively "generate binary" while staying within the constraints of text-based communication.
Binary, in computing, refers to data expressed in base-2, where each value is represented by a series of bits (0s and 1s). These bits can encode anything from numbers and letters to images, sound, and instructions for a computer program. While humans typically interact with higher-level representations like text or images, computers fundamentally operate on binary, interpreting sequences of bits according to file formats, protocols, or machine instructions.
In this work PDF-to-text libraries were used to sidestep binary blocks, so it is suprising to notes binary in sample outputs: actually we were trying to input and output the code/text between these binary blocks in PDF!
Discussion
This study highlights that positional logic and other forms of sub-token numerical data present a significant inference challenge for the chosen class of fine-tuned LLMs, even in cases where perplexity is low and model certainty appears high. To assess output quality, NLP-specific similarity metrics between hypothesis and reference documents were applied. While these metrics revealed a trend toward improved performance with increasing model complexity, no measurable gains were observed when incorporating meta-information into training or inference.
This suggests that the problem space is both nuanced and underexplored, yet potentially highly rewarding. Future work may therefore focus on several directions: the use of neural networks for accessibility scoring, methods for decomposing the task of PDF code generation into more tractable subtasks, the evaluation of emerging or more complex model classes, and the inclusion of additional document domains beyond those introduced here. Overall, the contribution of this work lies in its integration into an enterprise content management platform, the proposal of a basic methodological framework, and the provision of initial model tests and observations to inform subsequent research.
OOD? Uncertainty in LLM Inference
What “Perplexity” Captures
- Perplexity is a sequence-level measure derived from average negative log-likelihood.
- Lower values ⇒ model finds the sequence highly probable (more confident).
- Higher values ⇒ model finds the sequence unlikely (more uncertain).
- Only meaningful for causal LMs (autoregressive models). Tokenization affects scale, so compare models fairly.
Why Greedy Generations Often Show Very Low Perplexity
- Greedy decoding picks the highest-probability token at each step.
- This biases the output toward very likely tokens, yielding near-minimal loss and perplexity ≈ 1–2.
- To probe uncertainty, we want to either (a) evaluate perplexity conditional on the prompt (mask out prompt tokens), or (b) evaluate sampled outputs.
Conditional vs. Unconditional Scoring
- Self-likelihood: scoring the completion alone tends to be optimistic.
- Conditional perplexity: score completion while conditioning on the prompt (ignore the prompt in the loss). This better reflects “how likely is the model’s answer given the context?”
Token-Level Uncertainty Signals
- Predictive entropy (distribution spread over the next token): higher ⇒ more uncertainty; lower ⇒ more confidence.
- Top-1 probability: simple proxy for confidence at each step.
- We can aggregate these across the completion (e.g., mean entropy, mean top-1 prob).
Beyond Perplexity: Practical Uncertainty Estimation
- Sampling-based probes: one method is to enable sampling (temperature/top-p) and examine the distribution of perplexity/entropy across multiple draws.
- Monte Carlo Dropout: here you run multiple forward passes with dropout active; variance in logits/probabilities reflects epistemic uncertainty.
- Ensembles: different models (or checkpoints) on the same prompt; agreement ⇒ higher confidence, divergence ⇒ uncertainty.
- Semantic disagreement: or even, we cluster or compare generated answers by meaning; high diversity indicates uncertainty/ambiguity.
Interpreting Scales (Rules of Thumb)
- Perplexity near 1 on greedy outputs is normal and indicates very high confidence.
- Mean next-token entropy:
- Very low: sharply peaked distributions (confident).
- Moderate: some ambiguity among candidates.
- High: broad distributions (uncertain).
- Mean top-1 probability near 1 ⇒ confident; substantially lower ⇒ ambiguous next steps.
When Perplexity Can Mislead
- Distribution shift: PPL can be low on templated text but still wrong semantically.
- Length & truncation: long texts or context-window overflows require chunking; naive single-pass PPL may be invalid.
- Tokenization: different tokenizers change the numeric scale; avoid cross-tokenizer comparisons.
Recommended Workflow
We observe this recommendation in the literature, to …
- Generate completion (greedy for determinism or sampled for probing).
- Compute conditional perplexity on the completion (prompt masked out of the loss).
- Compute mean entropy and mean top-1 probability across completion steps.
- (Optional) Repeat with sampling, MC dropout, or ensembles to gauge uncertainty robustness.
- Log per-part metrics and flag unusually high-uncertainty segments for review.
Implementation Notes (HF/Transformers)
Final notes: we …
- Use the same model/tokenizer for generation and scoring.
- Concatenate
prompt || completion; mask prompt tokens in labels to get conditional metrics. - For entropy/top-1: use next-token logits at each step, softmax to probabilities, then aggregate.
- For long inputs, use sliding windows so scoring aligns with the model’s context length.
More Detailed Formulas
Perplexity
Perplexity is based on the negative log-likelihood (NLL) of the predicted sequence.
Given a sequence of tokens $x_1, x_2, \ldots, x_N$, and model probabilities $p(x_t \mid x_{<t})$:
- $\mathcal{L}$ is the mean NLL across the sequence.
- $\text{PPL}$ is the exponential of that loss.
- Intuition: Perplexity can be seen as the effective number of equally likely choices the model has at each prediction step.
Token Distribution Entropy
At each generation step $t$, the model produces a probability distribution over the vocabulary $V$.
If $p(v \mid x_{<t})$ is the probability of token $v \in V$ at step $t$:
- $H_t$ measures the uncertainty of the model’s prediction at time $t$.
- Low entropy → model confident (probability mass on few tokens).
- High entropy → model uncertain (probability mass spread across many tokens).
Average Entropy Across Sequence
You can also define an average entropy across the whole sequence:
\[\bar{H} = \frac{1}{N} \sum_{t=1}^{N} H_t\]Summary:
- Perplexity is a sequence-level measure of uncertainty.
- Entropy is a step-level measure of uncertainty in next-token prediction.
Note on Causal vs Masked LMs
Causal Language Models (CLMs)
- Examples: GPT-2, GPT-3, LLaMA, Falcon, Mistral.
- Training objective: Predict the next token given all previous tokens
→ $p(x_t \mid x_1, \ldots, x_{t-1})$. - Architecture: Decoder-only transformer with causal (uni-directional) attention.
- Generation: Naturally autoregressive, produces text one token at a time.
- Perplexity: Well-defined — directly measures how likely the model finds a sequence.
- Low perplexity ⇒ high confidence in predictions.
- High perplexity ⇒ model finds the sequence less likely (more uncertain).
Masked Language Models (MLMs)
- Examples: BERT, RoBERTa, DeBERTa.
- Training objective: Predict randomly masked tokens given full left and right context
→ $p(x_m \mid x_{\setminus m})$. - Architecture: Encoder-only transformer with bidirectional attention.
- Generation: Not designed for left-to-right rollout; needs iterative masking/filling.
- Perplexity: Not directly applicable, since the model doesn’t assign probabilities sequentially.
- Sometimes “pseudo-perplexity” is computed by masking each token in turn and scoring it.
- More computationally expensive and less aligned with training objective.
Why This Matters Here
- Our pipeline uses a causal LM → perplexity is a valid measure of model uncertainty on completions given prompts.
- For masked LMs, perplexity is misleading; instead use pseudo-perplexity or entropy-based confidence scores.
Observations
In evaluation, we generate a completion (either using greedy decoding for determinism or sampling for probing) and compute conditional perplexity on the completion, masking the prompt out of the loss. We also compute mean entropy and mean top-1 probability across completion steps, using next-token logits at each step. Interestingly, conditional perplexity for the top-performing models so far falls around ~1–1.5, which is extremely low, indicating the model is very confident and the tokens are highly predictable. However, low perplexity does not necessarily correlate with good output: we observe loops, repetition, filler, and a lack of valid PDF object code. This issue often reflects mode collapse or degenerate looping, where the model falls into repeating patterns (e.g., "BT … ET BT … ET" indefinitely). Such patterns are known to arise during fine-tuning, when the model learns to solve the training task narrowly but loses the ability to generalize to other forms of text. In this sense, low perplexity reflects predictability rather than quality—a phenomenon sometimes described as the likelihood trap – see also Zhang, Y., et al. (2020). Trading Off Diversity and Quality in Natural Language Generation.
More Testing Sets and Other Steps for this LLM Challenge
Finally, a publishable test set of 12 domain-specific documents was compiled: it is conceivable to carry this project forward by compiling more test sets, but, currently, LLMs might not be the tools to address this challenge in this form. Why?
- Conclusion: positional logic and other sub-token numerical data currently pose an inference challenge to the chosen class of (fine-tuned) LLMs, despite their low perplexity/high certainty, at least, and all LLMs potentially.
- Applying NLP-specific metrics for measuring reference similarities of the hypothesis documents: These were used to assess output quality, and while trends based on model complexity were observed, no improvements were detected when using meta-information during training or inference.
Outlook: This remains a nuanced problem with potentially large payoff. Future directions may include:
- (Tangent:) Exploring accessibility scoring via neural networks.
- Finding effective ways to break down the task of PDF code generation.
- Testing more complex current or future models.
- Expanding the test document set to include new domains, beyond the one introduced in this work.
Contribution: This work introduced an ECM platform integration, proposed a basic methodology, and conducted initial model testing and observations.